Session 9 and 10 : Cross Tabulation in SBD
In the 9th and 10th session of SBD, the session began with discussion about the types of variables.
The study of variables can be studied under the following main headings.
Continuous Variables: If a variable can take on any value between its minimum value and its maximum value, it is called a continuous variable.These can have fractional value, for example: salary, interest, age etc.
Category Variables: Variables which record a response as a set of categories are termed categorical. Such variables fall into three classifications: Nominal, Ordinal, and Interval. Nominal variables have categories that have no natural order to them. Examples could be different crops: wheat, barley, and peas or different irrigation methods: flood, furrow, and dry land. Ordinal variables, on the other hand, do have a natural order. Examples of these could be pesticide levels: high, medium, and low or an injury scale: 0, 1, 2, 3, 4, and 5.
Then we discussed a case study to discuss whether customers are satisfied with a particular store we do a cross tabular analysis.
Cross-tabulation is one of the most useful analytical tools and is a main-stay of the market research industry. One estimate is that single variable frequency analysis and cross-tabulation analysis account for more than 90% of all research analyses.Cross-tabulation analysis, also known as contingency table analysis, is most often used to analyze categorical (nominal measurement scale) data. A cross-tabulation is a two (or more) dimensional table that records the number (frequency) of respondents that have the specific characteristics described in the cells of the table. Cross-tabulation tables provide a wealth of information about the relationship between the variables.Cross-tabulation analysis has its own unique language, using terms such as “banners”, “stubs”, “Chi-Square Statistic” and “Expected Values.”hen a hypothesis is made using Chi square to check the hypothesis.
We did cross tab for Store and Service satisfaction variables. This is how we do crosstab.Analyse -> Descriptive Statistics -> Crosstabs
This is how we do crosstab.Analyse -> Descriptive Statistics -> Crosstabs Here we put store in rows as we are comparing for stores.For store 1 as we can see from the table 17.1% of the total people who visited store 1 are stronly negetive and 26.9% of the total people who are strongly negetive are negetive for store 1.Next we learned about Null Hypothesis and CHI-SquareThe null hypothesis in cross tab says that there is no relationship between the two variables we are testing.
Here we put store in rows as we are comparing for stores.For store 1 as we can see from the table 17.1% of the total people who visited store 1 are stronly negetive and 26.9% of the total people who are strongly negetive are negetive for store 1.Next we learned about Null Hypothesis and CHI-SquareThe null hypothesis in cross tab says that there is no relationship between the two variables we are testing.
Significance value - < 0.05 reject
> 0.05 accept
When it is more than 0.05 we accept it and it means there is no relation between the two variables.A chi-squared test, also referred to as chi-square test or 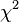 test, is any statistical hypothesis test in which the sampling distribution of the test statistic is a chi-squared distribution when the null hypothesis is true. Also considered a chi-squared test is a test in which this is asymptotically true, meaning that the sampling distribution (if the null hypothesis is true) can be made to approximate a chi-squared distribution as closely as desired by making the sample size large enough.Some examples of chi-squared tests where the chi-squared distribution is only approximately valid:
test, is any statistical hypothesis test in which the sampling distribution of the test statistic is a chi-squared distribution when the null hypothesis is true. Also considered a chi-squared test is a test in which this is asymptotically true, meaning that the sampling distribution (if the null hypothesis is true) can be made to approximate a chi-squared distribution as closely as desired by making the sample size large enough.Some examples of chi-squared tests where the chi-squared distribution is only approximately valid:
- Pearson's chi-squared test, also known as the chi-squared goodness-of-fit test or chi-squared test for independence. When the chi-squared test is mentioned without any modifiers or without other precluding context, this test is usually meant (for an exact test used in place of , see Fisher's exact test).
- Yates's correction for continuity, also known as Yates' chi-squared test.
- Cochran–Mantel–Haenszel chi-squared test.
- McNemar's test, used in certain 2 × 2 tables with pairing
- The portmanteau test in time-series analysis, testing for the presence of auto correlation
- Likelihood-ratio tests in general statistical modelling, for testing whether there is evidence of the need to move from a simple model to a more complicated one (where the simple model is nested within the complicated one).
One case where the distribution of the test statistic is an exact chi-squared distribution is the test that the variance of a normally distributed population has a given value based on a sample variance. Such a test is uncommon in practice because values of variances to test against are seldom known exactly. Then we did the correlation of various satisfactions.
Then we did the correlation of various satisfactions.
If the correlation value is high then if one variable is high than other correlation variable is also high.

 test, is any statistical hypothesis test in which the sampling distribution of the test statistic is a chi-squared distribution when the null hypothesis is true. Also considered a chi-squared test is a test in which this is asymptotically true, meaning that the sampling distribution (if the null hypothesis is true) can be made to approximate a chi-squared distribution as closely as desired by making the sample size large enough.Some examples of chi-squared tests where the chi-squared distribution is only approximately valid:, see Fisher's exact test).
test, is any statistical hypothesis test in which the sampling distribution of the test statistic is a chi-squared distribution when the null hypothesis is true. Also considered a chi-squared test is a test in which this is asymptotically true, meaning that the sampling distribution (if the null hypothesis is true) can be made to approximate a chi-squared distribution as closely as desired by making the sample size large enough.Some examples of chi-squared tests where the chi-squared distribution is only approximately valid:, see Fisher's exact test).

When the numbers get low, stop analysis.For any deep analysis take big sample space.
This was the concluding note of the session.
Roll No. 2013199
Group Members:
Nishant Renjith
Pranshu Agarwal
Prateek JainGroup Members:
Nishant Renjith
Pranshu Agarwal
Priyanka Sudan
No comments:
Post a Comment