SUMMARY OF 19th & 20th SESSIONS
MEAN :
In probability and statistics, mean and expected are used synonymous to refer to one measure of the central tendency either of a probability distribution or of the random variable characterized by that distribution.In the case of a discrete probability distribution of a random variable X, the mean is equal to the sum over every possible value weighted by the probability of that value; that is, it is computed by taking the product of each possible value x of X and its probability P(x), and then adding all these products together, giving  . An analogous formula applies to the case of a continuous probability distribution. Not every probability distribution has a defined mean; see the Cauchy distribution for an example. Moreover, for some distributions the mean is infinite: for example, when the probability of the value
. An analogous formula applies to the case of a continuous probability distribution. Not every probability distribution has a defined mean; see the Cauchy distribution for an example. Moreover, for some distributions the mean is infinite: for example, when the probability of the value 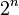 is
is  for n = 1, 2, 3, ....
for n = 1, 2, 3, ....
. An analogous formula applies to the case of a continuous probability distribution. Not every probability distribution has a defined mean; see the Cauchy distribution for an example. Moreover, for some distributions the mean is infinite: for example, when the probability of the value is for n = 1, 2, 3, ....
For a data set, the terms arithmetic mean, mathematical expectation and sometimes average are used synonymous to refer to a central value of a discrete set of numbers: specifically, the sum of the values divided by the number of values. The arithmetic mean of a set of numbers x1, x2, ..., xn is typically denoted by 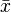 , pronounced "x bar". If the data set were based on a series of observations obtained by sampling from a statistical population, the arithmetic mean is termed the sample mean (denoted ) to distinguish it from the population mean (denoted
, pronounced "x bar". If the data set were based on a series of observations obtained by sampling from a statistical population, the arithmetic mean is termed the sample mean (denoted ) to distinguish it from the population mean (denoted  or
or  ).
).
, pronounced "x bar". If the data set were based on a series of observations obtained by sampling from a statistical population, the arithmetic mean is termed the sample mean (denoted ) to distinguish it from the population mean (denoted or ).
For a finite population, the population of a property is equal to the arithmetic mean of the given property while considering every member of the population. For example, the population mean height is equal to the sum of the heights of every individual divided by the total number of individuals. The sample mean may differ from the population mean, especially for small samples. The law of large numbers dictates that the larger the size of the sample, the more likely it is that the sample mean will be close to the population mean
MEDIAN :
In statistics and probability theory, the median is the numerical value separating the higher half of a data sample, a population, or a probability distribution, from the lower half. The median of a finite list of numbers can be found by arranging all the observations from lowest value to highest value and picking the middle one (e.g., the median of {3, 5, 9} is 5). If there is an even number of observations, then there is no single middle value; the median is then usually defined to be the mean of the two middle values, which corresponds to interpreting the median as the fully trimmed mid range. The median is of central importance in robust statistics, as it is the most resistant stat, having a breakdown point of 50%: so long as no more than half the data is contaminated, the median will not give an arbitrarily large result.
A median is only defined on ordered one-dimensional data, and is independent of any distance metric. A geometric median, on the other hand, is defined in any number of dimensions.In a sample of data, or a finite population, there may be no member of the sample whose value is identical to the median (in the case of an even sample size); if there is such a member, there may be more than one so that the median may not uniquely identify a sample member. Nonetheless, the value of the median is uniquely determined with the usual definition. A related concept, in which the outcome is forced to correspond to a member of the sample, is the medoid. At most, half the population have values strictly less than the median, and, at most, half have values strictly greater than the median. If each group contains less than half the population, then some of the population is exactly equal to the median. For example, if a < b < c, then the median of the list {a, b, c} is b, and, if a < b < c < d, then the median of the list {a, b, c, d} is the mean of b and c; i.e., it is (b + c)/2.
The median can be used as a measure of location when a distribution is skewed, when end-values are not known, or when one requires reduced importance to be attached to outliers, e.g., because they may be measurement errors.In terms of notation, some authors represent the median of a variable x either as 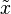 or as
or as  sometimes also M. There is no widely accepted standard notation for the median, so the use of these or other symbols for the median needs to be explicitly defined when they are introduced.
sometimes also M. There is no widely accepted standard notation for the median, so the use of these or other symbols for the median needs to be explicitly defined when they are introduced.
or as sometimes also M. There is no widely accepted standard notation for the median, so the use of these or other symbols for the median needs to be explicitly defined when they are introduced.MODE :
The mode is the value that appears most often in a set of data. The mode of a discrete probability distribution is the value x at which its probability mass function takes its maximum value. In other words, it is the value that is most likely to be sampled. The mode of a continuous probability distribution is the value x at which its proability density function has its maximum value, so, informally speaking, the mode is at the peak.
Like the statistical mean and median, the mode is a way of expressing, in a single number, important information about a random or a population. The numerical value of the mode is the same as that of the mean and median in a noormal distribution, and it may be very different in highly skewed distributions.
The mode is not necessarily unique, since the same maximum frequency may be attained at different values. The most extreme case occurs in uniform distributions, where all values occur equally frequently.
REGRESSION :
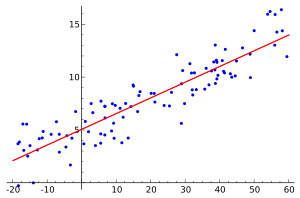
In statistics, regression analysis is a statistical process for estimating the relationships among variables. It includes many techniques for modeling and analyzing several variables, when the focus is on the relationship between a dependent variable and one or more independent variable. More specifically, regression analysis helps one understand how the typical value of the dependent variable changes when any one of the independent variables is varied, while the other independent variables are held fixed.
Regression models involve the following variables:
- The unknown parameters, denoted as β, which may represent a scalar or a vector.
- The independent variables, X.
- The dependent variable, Y LINEAR REGRESSION: In linear regression, the model specification is that the dependent variable,
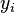 is a linear combination of the parameters (but need not be linear in the independent variables). For example, in simple linear regression for modeling
is a linear combination of the parameters (but need not be linear in the independent variables). For example, in simple linear regression for modeling  data points there is one independent variable:
data points there is one independent variable:  , and two parameters,
, and two parameters,  and
and 
- straight line:

In multiple linear regression, there are several independent variables or functions of independent variables.
Adding a term in xi2 to the preceding regression gives:- parabola:

Submitted by
Polisetti kartheeki
GROUP MEMBERS:
Nishid lad(2013176)
Priyatam(2013183)
kalyani(2013184)
Polisetti kartheeki(2013198)
Priyadarshi(2013211)
- straight line:
No comments:
Post a Comment